
Authors: Neha Singh, Jack Russo, Lewis Sonny-Egbeahie, Seyi Idowu, Minh Duong
Subject Matter Experts: Garth Barker-Goldie, Charanpal Matharu, Andrew Rice, John Onwuemeka
As Financial Services Institutions expand their client base, products, services, and business, appropriate use of Artificial Intelligence (AI) becomes essential across different parts of the organisation. Using reliable AI technology provides a competitive edge for banks to have a more organised, updated and well-informed KYC (Know Your Client) structure. It also allows them to materially improve data management.
We are a global team of Prospect 33 data scientists and active members of the Prospect 33 Global Data Lab. We built a solution to leverage external data for the initial purpose of KYC onboarding, the client lifecycle, and transaction monitoring to identify suspicious activity. Additionally, we wanted to build a solution that would be based on open source data (news and blog sites) surrounding a client’s or potential client’s business (e.g. new acquisition and business expansions). We developed an intelligent solution using advanced AI & machine learning methods to handle news data aggregation and analysis.
The solution represents the foundation of a comprehensive news aggregation and sentiment analysis tool which traces to original Client records within the Client Master data source. This involved creating a customized dataset for training purposes which consists of news articles categorized by sentiment and relevance to KYC.
Upon review it was clear that the sentiment analysis had multiple use case applications that included cross-selling and revenue opportunities.
We investigated various Classic Machine Learning (statistical algorithms that are capable of learning from data and making inference based on learned patterns) and Deep Learning Models (a set of layered artificial neurons that are analogous to a neural web in a human brain) to establish the baseline classifier for sentiment. After performing extensive experimental analysis, we found that the BERT (Bidirectional Encoder Representations from Transformers) model outperformed all other models and provided the highest accuracy and F1-score. We also worked on creating the data workflow by adding data sources from Google News, Yahoo Finance, and Google to enhance the dataset and implement model performance improvement. This included making the model more robust and able to classify news coming from any source more accurately. It also enabled the ingestion and aggregation of blogs, social news sites such as Reddit and a variety of mainstream news sources.
About the Data
The dataset used to train the model had a mix of approximately 10,000 financial and non-financial news articles. These articles were subsequently labelled for the sentiment, relevancy to KYC, and relevancy to sales following a predefined labelling rule. The goal was to correctly predict the sentiment of any given article, its relevance to KYC and/or Sales.
Upon completing data labelling, we performed some exploratory textual data analysis in order to understand some basic characteristics and structure of the training data such as word frequency and distribution, number of words present in each data instance, average number of characters in each word and so forth. We also employed topic modeling, wordcloud, Named Entity Recognition, word clustering, and N-gram models to reaffirm the data structural understanding. After carefully applying the word analysis, we procured the major themes in the news data revolving around fraud allegations, court cases (pending/decision/settlement), speculation regarding product or service expansion, product- or client-inclined news, various business development and growth opportunities, KYC details, etc. Each training data instance contains on average less than 100 words and covers the range of financial information associated with the known or new entities.
Model Building & Finalization
When we first began model building, we were confronted with training and testing a variety of machine learning models. How could we be confident that we had chosen the right text classification algorithm for the job? In the course of answering this question, we were able to automate the process of training, testing and comparing natural language processing models.
For each approach, the F1 Score from the precision and recall metrics using the relationships given below:

F1 simply quantifies the confident-level of our model performance hence, the predicted results. After testing a variety of models on independent data, the team concluded that deep learning BERT models provided the best F1 Score for KYC relevancy, Sales relevancy, and overall text sentiment.
Table 1. Classification metrics of trained models
Model | Model Type | Target | Accuracy | F1-Score |
|---|---|---|---|---|
Support Vector Classifier | Classical ML | KYC_relevancy | 0.74 | 0.73 |
KNeighborsClassifier | Classical ML | sales_relevancy | 0.80 | 0.71 |
Support Vector Classifier | Classical ML | sentiment_negative | 0.77 | 0.77 |
Support Vector Classifier | Classical ML | sentiment_neutral | 0.71 | 0.68 |
Support Vector Classifier | Classical ML | sentiment_positive | 0.79 | 0.70 |
BERT | Deep Learning | sentiment | 0.75 | 0.74 |
BERT | Deep Learning | KYC_Sales_relevancy | 0.84 | 0.70 |
BERT
BERT stands for Bidirectional Encoder Representations from Transformers. This is a Natural Language Processing Model built by researchers at Google Research in 2018. It is a deeply bidirectional model meaning that it learns information from both sides of a token’s context during the training phase.
BERT architecture comprises input, encoder, decoder and output layers which contain 12 transformer blocks and 12 attention heads for the base model, and 24 transformer blocks and 16 attention heads for the large model. We utilized the base model in this project because it was a lighter model and it performed well on our task. The input layer takes token embedding, segment embedding and positional embedding as input. The token embedding is a Wordpiece embedding for each word whereas the positional embedding contains information about the position of each token in the input. The segment embedding helps with information about sentences (for example, the segment embedding of a three-sentence input will be 0, 1 and 3, respectively).
Each encoder comprises a self-attention head and a feed-forward layer. The input embeddings flow into the first encoder in parallel and the output of the first encoder flows in parallel into the next encoder and so on until the data flows into the last encoder layer. An input undergoes 6 transformations in the self-attention layer following a conversion into 3 sets of vectors (query, key and value vectors) before it is normalized and fed into the feed-forward layer. The output of the feed-forward layers are also normalized. Each decoder comprises a self-attention head, an encoder-decoder attention and a feed-forward. The decoder functions similarly to the encoder; the major difference being that the self-attention only performs operations on earlier word positions following a masking operation on the future words positions. The decoder feeds into a fully-connected linear layer which passes its output to a softmax layer where word probabilities are computed.
BERT was pre-trained on a large unlabeled plain text corpus, the entire Wikipedia (about 2,500 million words) and Book corpus (800 million words). Its pre-training acts as a foundation of “knowledge” on which to build on making it perfectly fit for transfer learning. It can then be fine-tuned to a user’s specifications and adapt to the ever-growing corpus of searchable content and queries through the process called transfer learning. Due to the high performance capabilities of BERT on Natural Language tasks, we found it suitable for this project as the model just needed to be fine tuned to our specific task. Additionally, BERT outperformed all other traditional ML algorithms we tested as part of a rigorous model evaluation step.
Article Summarization
Summarization expresses the most important facts in a long article in a short and clear form. Different kinds of summarizer models were investigated, such as BERT summarizer, Latent Semantic Analysis (LSA), Newspaper3k summarizer, and Gensim. The team evaluated the performance of an LSA, Gensim, and BERT summarizer models against Newspaper3k summarization and found that the Newspaper3k summarization was comparable to the best performing BERT summarizer. We hence opted to use Newspaper3k for coding compactness and simplicity. Therefore, the articles from scraped unstructured sources were summarized using Newspaper3k.
For a client name search in Yahoo and Google, the URL links are gathered with the help of python packages, namely Selenium and BeautifulSoup, along with the GoogleNews API. From the list of URL links, the news articles were extracted using the library package Newspaper3k. Finally, Newspaper3k creates a summary of the article which was then fed to the BERT model for sentiment, sales relevancy, and KYC classification. The team evaluated the performance of an LSA, Gensim, and BERT summarizer models against Newspaper3k summarization and found that the Newspaper3k summarization was comparable to the best performing BERT summarizer, so opted to use Newspaper3k for coding compactness and simplicity.
This client news data acquisition and processing flow as described above is shown in the following figure.
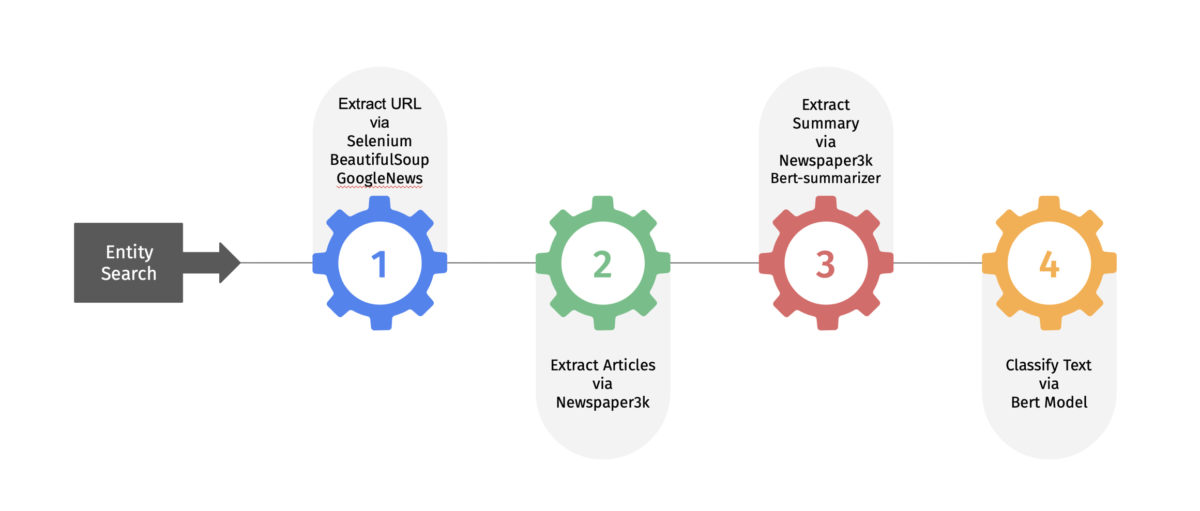
Data Storage
The client’s consolidated news search results were uploaded to Google BigQuery cloud storage. A table was created for each client containing the titles, posted dates, descriptions, sources, full articles, summaries, and the URL links. The sentiment, sales relevancy, and KYC predictions from the model were then appended to each of the client news samples. For existing client tables, repeated searches of client news mentions and classifications will be concatenated into the existing BigQuery table.
Model Improvement
To help the model better understand the nuances of classification for sentiment, sales relevancy, and KYC flagging, the final step in the machine learning workflow is to recruit the user to accomplish this task. A user can review selected prediction samples for accuracy and the mis-classified predictions can be corrected and added back to the training dataset. This feedback process was critical to the continual improvement of the model by helping to overcome the shortcomings of using a small training dataset. Notwithstanding a small dataset, it was more critical for a data-centric focused approach to have better data quality. The user feedback gave better data quality by having a more consistent labeling of targets.
Conclusion
Given a sound Client master database which is foundational for any such advanced data solution in this domain environment, our team successfully created a next step solution of a machine learning pipeline that identifies a Client or entity potential impact for the firm using mentions from news sources. Adhering to an agile framework, we iteratively completed the machine learning workflow phases of data collection and preprocessing, building traditional and deep learning models, tuning and model selection based on the F1 score on unseen test data, and finally, created a predictive user interface with feedback for model improvement.
During the project sprints, we were immersed in deep discussions with industry experts on Anti-Money Laundering (AML), the Know-your-Client (KYC) Process, Data Quality (DQ) Framework, Master Data Management and other key domain topics. Other considerations were made throughout aspects of the program such as dataset labeling, data exploration, and model improvements toward target use-cases such as Anti-Financial-Crime (AFC), Unauthorized & Rogue Trading and other such key Risk challenges which could leverage the work. We also had the opportunity to sharpen our data science and data engineering skills while acquiring new tools and methods. Best of all, we enjoyed the spirited collaboration between like and sharp minds.
Prospect 33's Global Data Lab
Prospect 33’s Global Data Lab is an AI & Machine Learning Solutions Laboratory which leverages Prospect 33’s deep domain and subject matter expertise in financial services, investment banking and capital markets. Its purpose is to conceptualise, design, and develop intelligent (AI & ML) solutions to significant challenges within the industry hereto unsolved by existing legacy technology solutions and processes.
Staffed with a global team of data scientists and financial services subject matter experts, the GDL focuses on solutions surrounding Risk, Anti-Financial Crime (AFC), Know Your Client (KYC) and Anti-Money Laundering (AML) as well as revenue generation.
This article was prepared by one such team of data scientists and experts to talk about recent findings leveraging Deep Learning and Machine Learning solutions for the purpose of KYC for onboarding, the client lifecycle, and transaction monitoring to identify suspicious activity. Additional use-cases were also reviewed including revenue generation and internal cross-selling intelligence.